Tissue segmentation in digital pathology is one of these weird little problems where it seems like it should be trivial, where in fact in many situations it is trivial, yet if you need a robust solution with a reasonable amount of precision, it is suprisingly difficult to get it right. This is something that we examine in our latest preprint, accepted into the SIPAIM 2023 conference [read as HTML - read as PDF], written with Arthur Elskens, Olivier Debeir and Christine Decaestecker.
What are we trying to do?
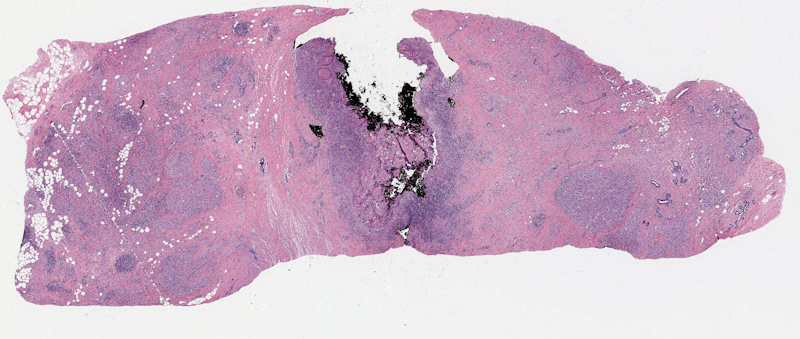
This is a situation that most developpers who had to work with digital pathology images had to deal with at some point or another: you have a very large image with some tissue regions, and a lot of light gray “background,” where the backlight from the microscope shines through the glass slide.
Exemple of a whole-slide image from a breast cancer sample (source: TCGA, case TCGA-AC-A2FB)
The goal is to clearly separate the tissue region from the background region. There are many potential reasons for that. One of the most common is when we are extracting patches for training a deep neural network: we don’t want to extract tiles in the background region, where there is no useful information to be found.
Another case is when we are trying to quantify stuff, such as the percentage of the tissue that is covered by, for instance, tumoral cells. It’s important in that case to have a good estimation of what the total tissue area is. Kleczek et al.1 also uses tissue segmentation to get a more accurate estimation of the stain colors, for a process called stain deconvolution which is also fairly common.
Those different cases have very different requirements: for the patch extraction, for instance, we don’t really care if it’s super precise. For quantification processes, however, we do.
How do we do it?
When we look at the litterature, it’s quickly apparent that most people just kinda wing it (which is what I was doing up to know as well, to be honest). Everyone has a slightly different but relatively similar pipeline, which most of the time can be summed up in a few steps:
Channel reduction: convert the 3-channel color image into a single-channel “grayscale” image.
Thresholding: determine the best value that separates background from non-background in this single-channel image.
Post-procsesing: clean-up the segmentation mask, typically with some morphological operations and by filling any holes within the tissue region.
A few algorithms have also been developped a bit more rigorously, such as FESI2 or EntropyMasker3, but they still follow mostly the same pipeline.
Our study
The steps that seems the most important in this process is the channel reduction step: how do we transform the image so that the value of the pixels in the single-channel image are well-correlated with whether they are within the tissue region or not.
The main characteristic of the background region is that it’s light, so a common choice is to simply use the regular grayscale transform (or “inverted” grayscale so that tissue regions appear brighter than background regions). Another characteristic is that it’s grayish, or “desaturated.” So we can use the saturation in the HSV colorspace. Another approach (used for instance in the VALIS registration software4) is to first estimate the color of the background region (by looking at the brightest pixels), then compute a color distance from each pixel to this estimated background color. Pixels in the tissue should be “further” in colorspace.
We can also use the other main charactersitic of the background region: that it’s homogeneous. This is the approach from EntropyMasker: to use the local entropy – or, in other works, the Laplacian or the output of an edge detection algorithm – which will be higher in “textured” regions (such as the tissue) and lower in the background regions.
The goal of our study was to evaluate whether one or some of those approaches, all commonly found in the litterature, are better than the others.
Our results
We use annotated data from Bándi et al.5 and from the TiGER challenge6. Five slides from Bándi and 62 from TiGER are used as a development / learning set. Five slides from Bándi and 31 from TiGER as a test set. We worked using a low magnification level corresponding to a resolution of around 15µm/px in all experiments.
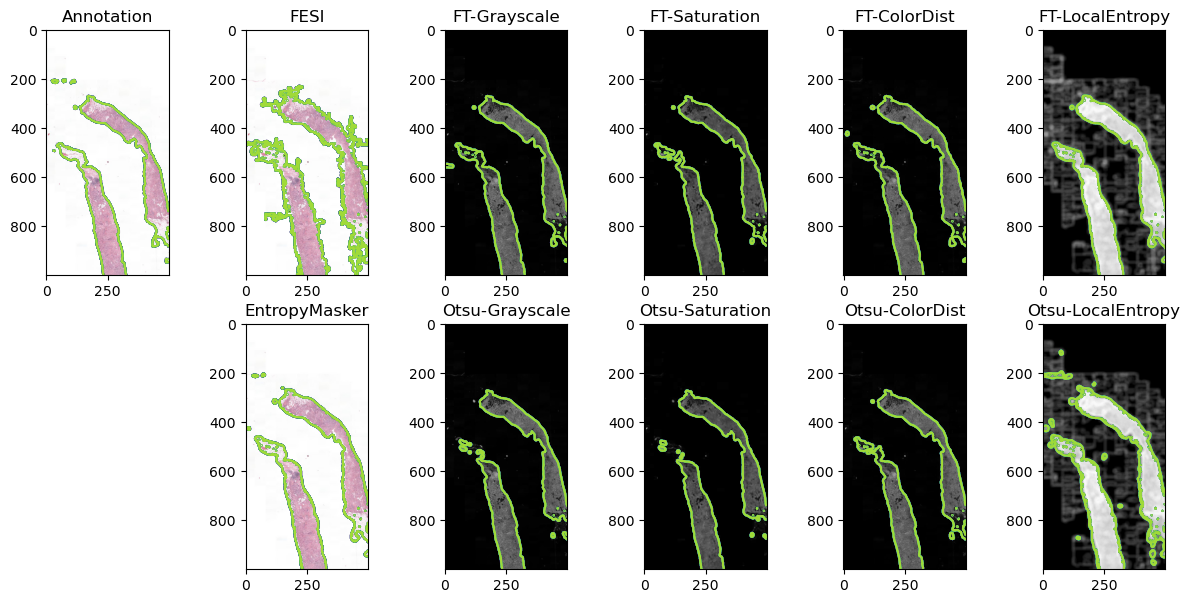
We first analyzed the separability of the tissue and background value distributions in the different single-channel options on the development set, and find that the local entropy provides the best separability, and the grayscale the worst.
We then look at the results of a basic pipeline of channel reduction, median filter, thresholding and morphological post-processing, and compare the four channels’ results according to the Intersection over Union metric. For the thresholding step, we use either a “learned” threshold (based on the development set), or the Otsu algorithm. FESI and EntropyMasker results are also tested for comparison.
Results on a representative image of the test set. The contours of the masks are overlaid on the RGB image (for the annotations, FESI and EntropyMasker) and on the single-channel representations (for the fixed (FT) and Otsu thresholds).
Our main conclusions are:
Our results demonstrate that transforming the RGB image to grayscale, as is very commonly done for tissue segmentation, is a suboptimal choice that should generally be avoided. Better channel reduction choices are available, focusing either on the colorization of the tissue compared to the background (e.g. with Saturation or ColorDist), or on the texture (e.g. with LocalEntropy). Pipelines with many handcrafted steps such as the one proposed in EntropyMasker may be unecessarily complex, as a very simple pipeline obtain very similar results as long as the right channel reduction step is applied.
What about deep learning ?
Tissue segmentation can certainly also be performed using deep convolutional neural networks. Bándi et al., for instance, showed very good results using U-Net. We decided against including such methods in our analysis, however:
We purposefully chose not to focus on deep learning solutions in this study. Often, one of the objectives of tissue segmentation is to have a very simple and quick method that offer a result that doesn’t need to be pixel-perfect. Making simple, classical pipelines more robust and reliable can allow us to get good results while wasting less computing resources.
I think that, in general, we should try to find the “simplest” solution to a problem. For my future needs in tissue segmentation, I’d much rather have a robust, reliable pipeline based on channel reduction and basic operations (that can easily be translated to any framework and included in any pipeline without much fuss) rather than to have a big trained neural network that will require some heavy maintenance to keep up to date with the latest versions of deep learning libraries. I have some neural networks that were trained two years ago and which are already annoyingly complicated to run now. I’d feel a lot more comfortable with the kind of pipeline that we studied here.
So do we have a robust solution?
First we have to refine the other steps of the pipline, most particularly the post-processing, and to potentially combine different thresholds. The homemade pipeline that I used until now thresholded on a combination of the grayscale and saturation channels. I’ll likely change that to rather use saturation and color distance or saturation and local entropy.