The machine learning pipeline
Adrien Foucart, PhD in biomedical engineering.
This website is guaranteed 100% human-written, ad-free and tracker-free. Follow updates using the RSS Feed or by following me on Mastodon
Adrien Foucart, PhD in biomedical engineering.
This website is guaranteed 100% human-written, ad-free and tracker-free. Follow updates using the RSS Feed or by following me on Mastodon
Solutions to machine learning tasks can generally be represented in the form of a pipeline, going from the "input", which is the raw data that it works on, to its "output", which will be its solution to the task.
More accurately, there will typically be two pipelines: one for learning, and one for "production", when the trained model can be applied to its task on new data.
Let’s go back to the "face detection" problem from my previous post. The learning pipeline, which would be applied to all the examples in the training dataset, could look something like this:
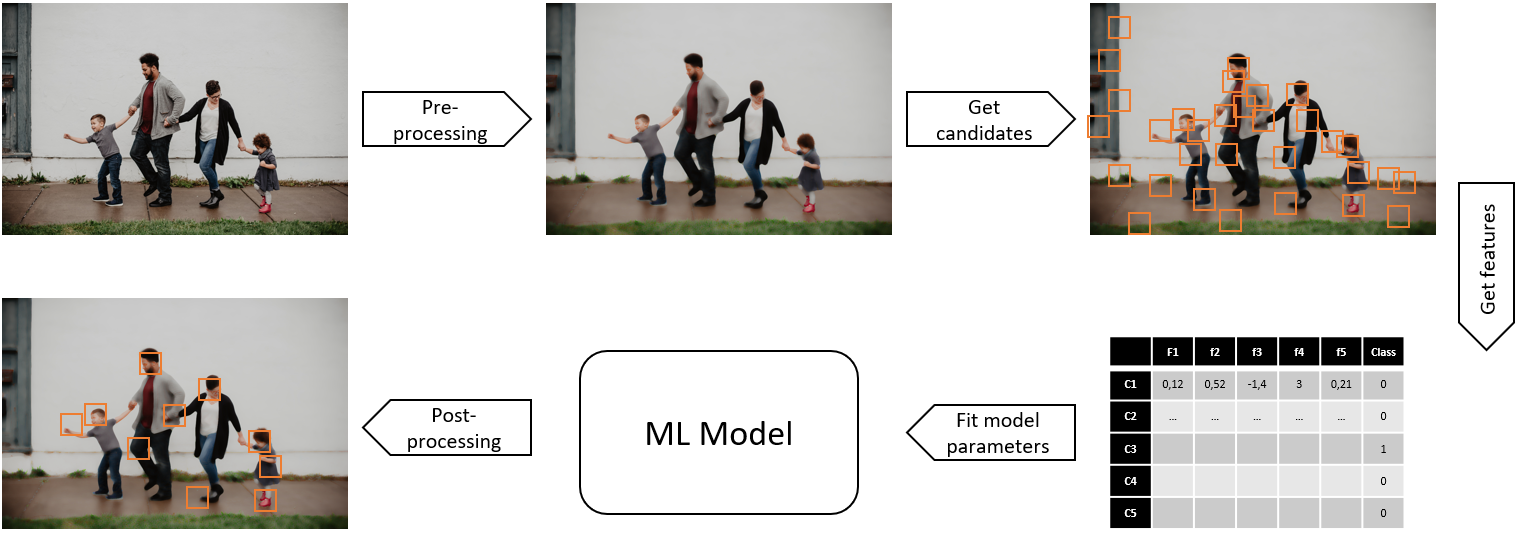
Let's take it step by step.
First, we apply some pre-processing to the image. The goal of pre-processing is to make global transformations that reduce the signal of whatever we don't want to detect and increase the signal of what we want to detect. A common step would be noise reduction, or edge detection.
Then, we try to detect "candidates". This step is also very common in image processing tasks. The goal is to not train the model not on one large image with several faces in it, but on many small images with a maximum of one face, as it will make the problem less complex. We could just cut the image into small fragments, or we can first use a simple metric (for instance: sample regions from areas where some borders are present) to compute possible candidates.
Third, we can compute useful features on those fragments. Feature extraction means that we replace the pixel information by a set of vectors of statistics computed on these pixels. It could be the mean value, the standard deviation, but also more complex things like the gradient directions or the presence or absence of certain pre-determined patterns. After this step, we will have replaced our image by a set of vectors. In other words, we now have our data "points", each feature corresponding to a dimension in a possibly highly dimensional feature space. If we only have two features, we could represent every candidate as a point in 2D, as we did with the "movie" data from the previous post.
Step 4 is what we generally think of when talking about "training a machine learning model": fitting the parameters of the model based on the features and the available annotations (e.g. does the fragment contain a face or not?)
Finally, we would probably have to apply some post-processing to the output of the model. This would mean taking the prediction for each fragment, putting the "positive" predictions back on the original image, and possibly using some additional rules to clean up the results. For instance: if we have two fragments which are mostly overlapping, we could merge them into one single face.
The parameters of the machine learning model are those optimized in step 4. But we also have to train the hyper-parameters of the whole pipeline: what type of pre-processing, how do we determine the candidates, which features we choose, what post-processing rules, etc...
Once the model is trained, it could then be used "in production" with the adapted pipeline on previously unseen images:
So, what's different about "Deep Learning"?
In this case, the main things that would change if we used a Deep Learning model would be to remove the pre-processing step, and to merge the feature extractions and model optimization steps into one, as illustrated below.
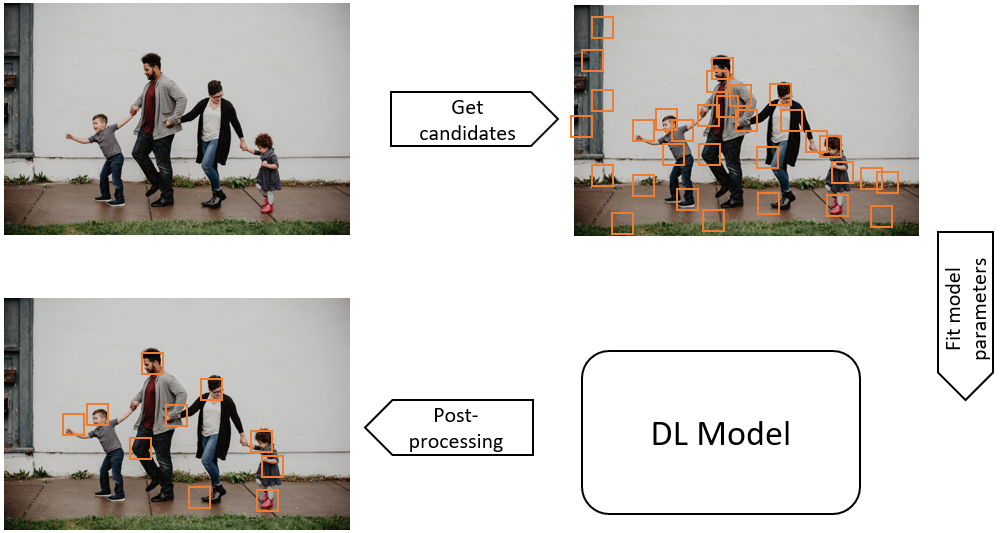
The reason for that is that Deep Learning method work best by reducing the "human bias" from the equation. If pre-processing is needed, the Deep Learning model should be able to find it by itself. If some features are more useful than others, the model should decide it find them from the raw data, not use those that the researcher thought about including in its tests.
It's important to note that, even with a Deep Learning method, there are still a lot of hyper-parameters outside of the network itself. We will very rarely see, for instance, a Deep Learning solution where we just dump the entire images in the network along with the position of all the faces and expect the network to learn from that. This would make the problem extremely complex, and therefore require a very large network, a huge number of examples (and, therefore, a huge amount of time-consuming annotations), and an unrealistic amount of time to train, unless you're Google.
That's why it’s always dangerous to reduce an algorithm only to the specific architecture of neural network used: many choices are made along the way which influence the end result just as much.
In the next article, we will look at the building blocks of most Deep Learning models: the different layers that form deep neural networks.