So... what's Deep Learning?
Adrien Foucart, PhD in biomedical engineering.
This website is guaranteed 100% human-written, ad-free and tracker-free. Follow updates using the RSS Feed or by following me on Mastodon
Adrien Foucart, PhD in biomedical engineering.
This website is guaranteed 100% human-written, ad-free and tracker-free. Follow updates using the RSS Feed or by following me on Mastodon
It seems like Deep Learning should have an easy, clear-cut definition. Yet... Wikipedia, on this topic, displays a remarkable example of circular citation - or Citogenesis, as the always-relevant XKCD would put it. The Wikipedia definition is a "summary" of five definitions from a Microsoft Research paper, most of which are themselves taken from earlier versions of the same Wikipedia article.
The most direct definition from a reputable source that I could find is probably from the "Deep Learning" Nature Review of AI-superstars Yann LeCun, Yoshua Bengio and Geoffrey Hinton (emphasis mine):
Deep learning allows computational models that are composed of multiple processing layers to learn representations of data with multiple levels of abstraction.
In a slightly more convoluted way, Ian Goodfellow, Yoshua Bengio (again) and Aaron Courville, in their "Deep Learning" book, introduce the topic this way (emphasis mine):
The true challenge to artificial intelligence proved to be solving the tasks that are easy for people to perform but hard for people to describe formally—problems that we solve intuitively, that feel automatic, like recognizing spoken words or faces in images. (...) A solution is to allow computers to learn from experience and understand the world in terms of a hierarchy of concepts, with each concept defined through its relation to simpler concepts.
These definitions basically boil down to: it's AI, with machine learning, with layers. So... What's machine learning? And, while we're at it, what is AI?
The history of Artificial Intelligence as a practical, computer-science-related field of research, goes back to the early days of computers themselves, around and right after World War II. The "ultimate goal" of AI, as illustrated in Alan Turing's best-known paper [3], was to create a computer which could be - at least in specific conditions - indistinguishable from a human.
This, unsurprisingly, is a difficult task. In fact, this particular goal, which is now generally referred to as "Artificial General Intelligence", is still mostly the domain of science-fiction.
One of the early avenues of research in AI, in the tradition of "trying to replicate human intelligence", was the artificial neuron. As early as 1943, McCulloch and Pitts [4] proposed a way to represent neurons in a mathematical model which could be replicated on a computer. They were followed by many others, but while their research was interesting, it proved to be largely impractical. Neural networks, quite simply, did not work. Artificial (General) Intelligence seemed altogether impossible. If AI as it was conceived couldn't be done, the next best thing was to change the definition of AI to something more forgiving.
In "Artificial Intelligence: foundations of computational agents" [5], Poole & Mackworth propose such a definition. AI, in their view, studies computational agents (which are agents whose actions and decisions can be implemented in a physical device, like a computer) that act intelligently, which means that it has actions appropriate for its circumstances and its goals, is flexible to changing environments and changing goals, and learns from experience.
This places any artificial intelligence in the context of task or problem solving. The job of an AI is not to be "like a human", but to have "human-like" (or better-than-human) capabilities in one or several specific tasks.
An interesting aspect of AI as defined by Poole & Mackworth is the capacity to learn from experience. Machine Learning is a subset of AI dealing with this particular aspect of "intelligence": how can a machine learn from experience?
To understand the basic idea of Machine Learning, it's interesting to look at one of its earliest algorithms, "Nearest Neighbor", with a version described already in 1951 [6].
Let's take an example. Imagine that you are a Big Streaming Company, and you want your AI to decide which movies or series in your catalog you should recommend to a particular user. Let's assume that you actually want to recommend something that the user will like, and not just something that you want to promote. For every movie or tv series, you have two pieces of information: how much violence, and how much comedy there is, as a percentage of the total runtime of the movie. For everything that the user has already seen, you also know (don't ask how) if he liked it or not.
You could therefore represent all of the movies that the user has seen on a nice graph, like this:
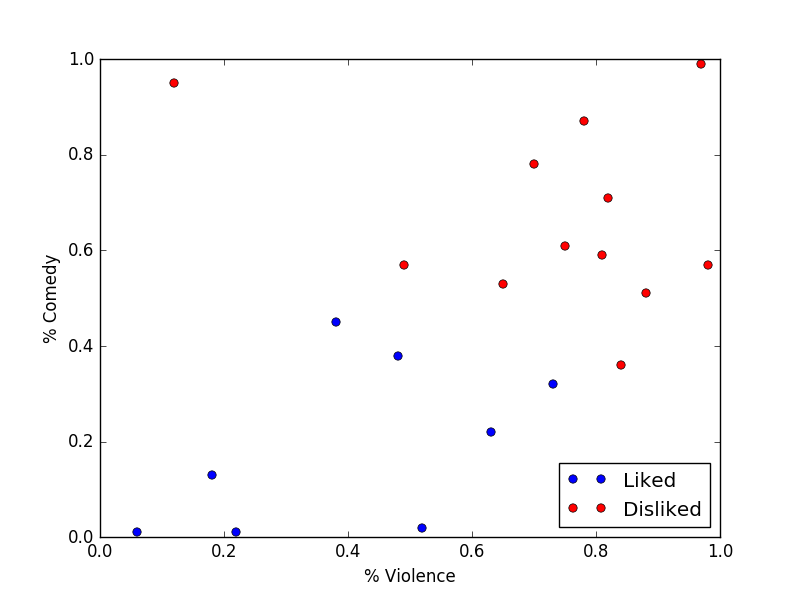
What you do know is that you take the movie that you want to recommend, and you also put it on the same graph. Then, you check if the closest point is something that the user liked or not. If not, you don't recommend the movie.
Obviously, this is a ridiculous example, but the main idea is there: the algorithm uses past experience to predict new behaviour. Of course, this will work a lot better if you have more data, and if you have better ways of describing this data.
There are many, many, more complex, more accurate algorithms in Machine Learning. But in the end, they fundamentally do the exact same thing: put all of the data (the "past experience") into some space that describes is as best as possible, and then find in that space a "Rule" that best predicts what to do with any future event. This rule can usually be as simple as a straight line (or to be precise in the more-than-two-dimensions case, an hyperplane) dividing the "space" in two, or be an intricate function with millions of parameters able to model any boundary shape, as in modern artificial neural networks.
While diverse machine learning algorithms such as Decision Trees, Support Vector Machines, and many others were being developped, the "artificial neural network" world was not completely inactive. One of the major issues with neural networks - how to efficiently "train" them with new examples - was vastly improved upon in 1986 with the backpropagation algorithm [7], which is still used today. In 1989, Yann LeCun and his team used it in what is now considered one of the first practical application of "modern" artificial neural networks, to recognize hand-written ZIP codes for the US Postal system [8].
In 1997, IBM's Deep Blue beat world champion Gary Kasparov in a six-game chess match [9]. In terms of public perception, this certainly gave AI enthusiasts a boost. Deep Blue, however, was an "Intelligence" only if you used the most forgiving definition. It didn't learn anything, it didn't reason anything: it was a pure, brute-force mechanism. Deep Blue simply took the current situation of the game, and computed all possible outcomes for all possible moves, for the next 10 to 20 moves. It did use "previous experience", in the form of thousands of previously played human-vs-human grandmaster games, to determine what a "winning move" was. But in the end, it mostly relied on the fact that chess is a game with fixed rules and a finite amount of outcomes. It worked because it had more processing power than what was previously available, not because it was innovative.
LeCun's success put neural networks back on the map, but they were still a curiosity. In most applications, they were impractical, took way too long to train, and didn't usually perform better than other machine learning approaches. But with the 21st century came two game changers in the machine learning world: Big Data and fast GPUs. Big Data - the ability to store huge amount of data on everything, thanks to cheap hard drives - gave us the ability to improve machine learning in general. Fast GPUs made training larger, more useful neural networks a reality. Quoting Dan Cireşan and his colleagues in 2010:
All we need to achieve this best result so far are many hidden layers, many neurons per layer, numerous deformed training images, and graphics cards to greatly speed up learning.
Around the same time, the idea that "larger" neural networks were actually "deeper" neural networks, with neurons organized in "layers", each layer connected to the next starting from the raw data all the way up to the output, became common usage.
By 2012, the achievements of "Deep" neural networks became impossible to ignore. On ImageNet, the largest visual object recognition challenge, Alex Krizhesvsky's AlexNet [11] dominated that year's field. Deep Learning approaches have since then consistently beaten "classical" machine learning methods on about everything. Most predominantly, it has become the standard solution for computer vision and language processing. In the world of AI, Deep Learning is now the law of the land.
To summarize:
These definitions are fuzzy. The boundaries between Deep Learning and "non-deep" Machine Learning are unclear, as are sometimes the boundaries between Machine Learning and "old fashioned AI". That's fine: we don't need every method to fit into a well-defined box.
All right. Now that we have defined what Digital Pathology and Deep Learning are, the next question will be: how has Deep Learning been applied to Digital Pathology?